
Apples KI-Wette: Kann Privatsphäre gegen Power gewinnen?
Artikel anhörenAutomatisch generierte Sprachausgabe

Während Google und Microsoft ihre KI-Systeme mit riesigen Mengen an Nutzerdaten aus der Cloud trainieren, geht Apple einen völlig anderen Weg – einen, bei dem Datenschutz statt Datensammlung den Kern der künstlichen Intelligenz bildet.
Privatsphäre als Eckpfeiler
Seit Jahren positioniert sich Apple als das Technologieunternehmen mit dem stärksten Fokus auf Privatsphäre. Im Zeitalter der KI ist dieser Ruf zugleich Vorteil und Herausforderung. Denn während Konkurrenten auf reale Nutzerdaten setzen, muss Apple alternative Wege finden, um seine Plattform Apple Intelligence zu trainieren.
Das Unternehmen will beweisen, dass fortschrittliche KI auch ohne die Ausbeutung persönlicher Daten möglich ist. Doch dieser Ansatz bedeutet zugleich, dass Apple langsamer vorankommt als andere Tech-Riesen.
Synthetische Daten: Nützlich, aber begrenzt.
Anstatt echte E-Mails, Nachrichten oder persönliche Dateien zu sammeln, erzeugt Apple synthetische Daten – künstliche Inhalte, die echten Dokumenten ähneln. Damit trainiert das Unternehmen Funktionen wie Textzusammenfassungen oder Schreibvorschläge.
Der Vorteil: Keine realen Inhalte verlassen das Gerät.
Der Nachteil: Synthetische Daten bilden die feinen Nuancen menschlicher Kommunikation nur unzureichend ab. Das führt dazu, dass die Modelle weniger zuverlässig Trends erkennen oder Fehler vermeiden.
Diese Grenzen wurden bereits sichtbar: Anfang 2025 verzögerte Apple ein Siri-Update und deaktivierte vorübergehend KI-generierte Nachrichten-Zusammenfassungen, nachdem Fehler gemeldet worden waren.
Der Hybrid-Ansatz: Differenzielle Privatsphäre
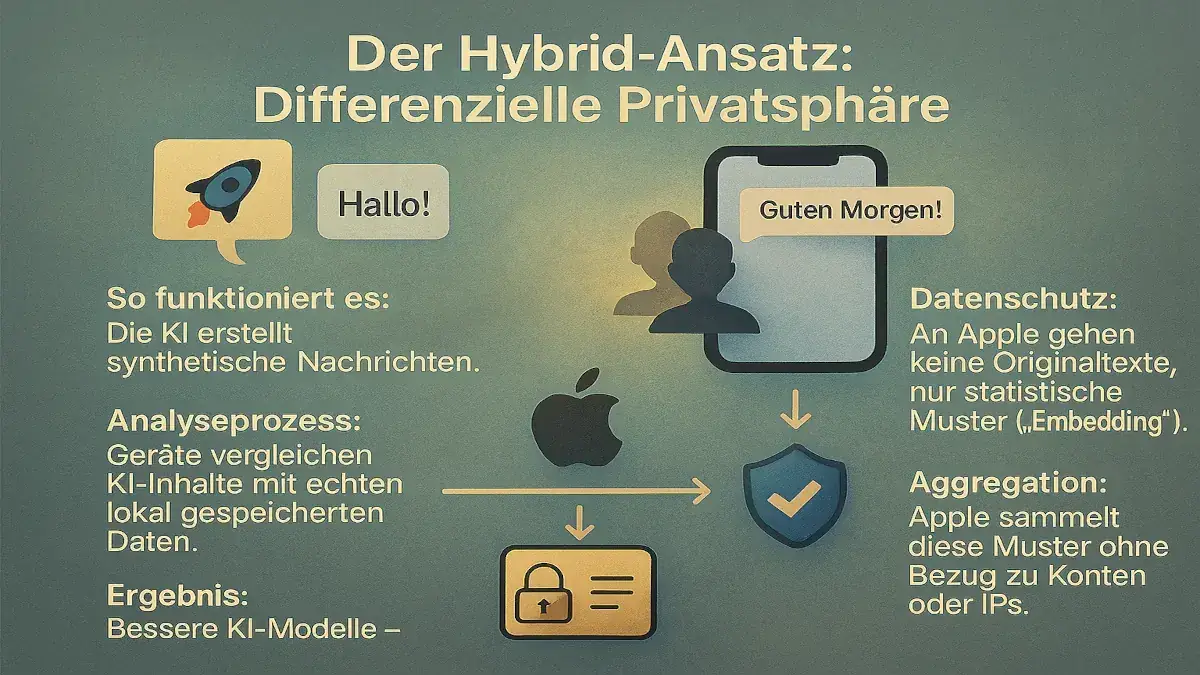
Um die Lücken zu schließen, setzt Apple auf differenzielle Privatsphäre – eine Methode, die anonymisierte Nutzersignale mit synthetischen Beispielen kombiniert.
So funktioniert es:
- Die KI erzeugt synthetische Nachrichten.
- Geräte, deren Nutzer den Analysen zugestimmt haben, vergleichen diese mit echten Inhalten, die lokal gespeichert sind.
- An Apple wird nicht der Originaltext gesendet, sondern nur sogenannte „Embeddings“ – statistische Muster wie Länge, Thema oder Tonalität.
- Diese Daten werden von Apple aggregiert, ohne dass ein Bezug zu Konten, IP-Adressen oder individuellen Nutzern entsteht.
Das Ergebnis: Bessere Modelle, ohne dass persönliche Daten jemals in die Cloud gelangen. Die Teilnahme ist freiwillig und standardmäßig deaktiviert.
Erste Einsatzgebiete
Bereits heute nutzt Apple diesen Ansatz bei Genmoji, einer Funktion, die personalisierte Emojis aus Texteingaben erstellt. Dabei erkennt die KI häufige Muster, ignoriert aber seltene oder einzigartige Eingaben, um Rückschlüsse auf Einzelpersonen zu verhindern.
Schrittweise überträgt Apple diese Technik auch auf andere Apple-Intelligence-Funktionen: Textzusammenfassungen, Schreib-Tools und Benachrichtigungs-Cluster. Langfristig soll sie auch in den Bereichen Gesundheit, Produktivität und Kommunikation eine Rolle spielen.
Das große Ganze
Mit synthetischen Daten, differenzieller Privatsphäre und On-Device-Analysen will Apple eine KI schaffen, die Grenzen respektiert. Öffentliche Inhalte werden zusätzlich gefiltert, damit sensible Daten wie Kreditkarten- oder Ausweisnummern gar nicht erst verarbeitet werden.
Die langfristige Vision reicht über Emojis hinaus: Apple möchte, dass Geräte Stimmung und Kontext verstehen – und so eine Art „digitalen Zwilling“ erschaffen, der Nutzer im Alltag unterstützt, ohne ihre Privatsphäre preiszugeben.
Vertrauen statt Tempo
Dieser Kurs hat seinen Preis. Apples KI mag weniger leistungsfähig wirken als die datenhungrigen Modelle von Google und Microsoft. Doch Apple setzt darauf, dass Vertrauen wichtiger ist als Geschwindigkeit.
In einer Welt, in der persönliche Daten längst zur Währung geworden sind, positioniert sich Apple als das Unternehmen, das sagt: Man muss seine Privatsphäre nicht aufgeben, um von KI zu profitieren.